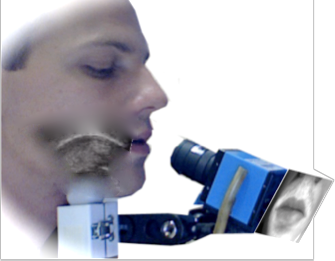
Development of a Silent Speech Interface
Driven by Ultrasound and Optical Images of the Tongue and Lips
T. Hueber, E. L. Benaroya, G. Chollet, B. Denby, G. Dreyfus, M. Stone
Development of a Silent Speech Interface
Driven by Ultrasound and Optical Images of the Tongue and Lips
T. Hueber, E. L. Benaroya, G. Chollet, B. Denby, G. Dreyfus, M. Stone

Corpus-based synthesis driven by video-only data
with a 100% correct phonetic decoding
Example 1a (Speaker A - without prosody adaptation) :
Example 1b (Speaker A - with prosody adaptation) :
Example 2 (Speaker A - with prosody adaptation) :
Example 3 (Speaker A - with prosody adaptation) :
Corpus-based synthesis driven by video-only data
with a 80% correct phonetic decoding
Example 4 (Speaker A - with prosody adaptation):
Corpus-based synthesis driven by video-only data
with a 60% correct phonetic decoding
(Typical performance of the current system)
Example 5 (Speaker A - with prosody adaptation):
Example 6 (Speaker A - with prosody adaptation):
Sound examples